How to test your LLM prompts (with examples)
Key takeaways
- Test your prompts regularly. Testing will make sure your outputs are accurate, relevant and cost-efficient (and that you minimize unnecessary API calls).
- Systematically improve your prompt. Log your requests, create prompt variations, test on production data or golden datasets, evaluate outputs, then deploy the best-performing prompt to production.
- Choose the right evaluation method. Use real user feedback for post-deployment, human evaluation for nuanced, subjective tasks, and LLM-as-a-judge for scalable, automated evaluations.
Introduction
Large Language Models (LLMs) are sensitive to prompt changes, where even minor wording changes can dramatically alter output. Untested prompts risk generating factually incorrect information, irrelevant responses, or unnecessary and expensive API calls. In this blog, we talk about how you can evaluate LLM performance and effectively test your prompts.
Your workflow to generate higher quality prompts might look like this:

Each prompt modification can trigger unexpected cascading effects, so engineers building with LLMs invest significant time meticulously designing and iterating prompts to create more robust AI applications.
In this blog, we will cover:
- 5 best prompt experiment tools for AI applications
- How to properly test your prompts
- How to evaluate prompts before and after deployment
- Method 1: Real user feedback
- Method 2: Human evaluators
- Method 3: LLM-as-a-judge
- Why prompt evaluation is important
- Examples
5 best prompt experiment tools for building AI apps
We hand-picked a few tools that support all of the following, along with comprehensive logging, dataset export capabilities and detailed performance tracking: Helicone, Langfuse, Arize AI, PromptLayer and LangSmith. Here's a quick comparison:
| Prompt Management | Playground | Evaluations | Experiments | Open-source | Testing with real-world data | |
|---|---|---|---|---|---|---|
| Helicone | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Langfuse | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Arize AI | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| PromptLayer | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ |
| LangSmith | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
Components to improve LLM prompts
Data collection
You need high-quality input variables to create high-quality prompts. A common practice is to use “golden datasets” - data that’s meticulously cleaned and labeled - to tune your prompt for problems that are easily reproducible.
Teams like QA Wolf use a new approach by randomly sampling production data, which represents actual user interactions and offers a more accurate representation of real-world use cases. QA Wolf leverages Helicone to monitor their agents and run systematic experiments, iteratively refining them to achieve 100% accuracy.
Prompt management
Think of it like Git for prompts. Prompt registries are specialized tools to help engineers version, manage or improve prompts, and roll back to a previous version easily.
Prompt playgrounds
Playgrounds are interactive environments that helps engineers iteratively test and refine their prompts. Notably, playgrounds enable rapid prompt iteration, testing against real-world data, and fine-tuning of model parameters and metadata configurations like top_k.
Evaluators & scores
Feedback is essential for continuous improvement. The best tools analyze LLM outputs by assigning qualitative and quantitative scores such as tone alignment and Semantic Similarity. They make it easy to compare different prompt variations and help engineers justify prompt changes with data before pushing to production
Experiment with prompts in Helicone ⚡️
Quickly iterate prompts, test with production datasets and evaluate with custom metrics. Join to get exclusive access.
How to properly test your prompts
Properly testing your prompts involves setting up a systematic workflow that iteratively improves performance. This process ensures you’re equipped to handle dynamic scenarios, minimize errors, and optimize user experience.
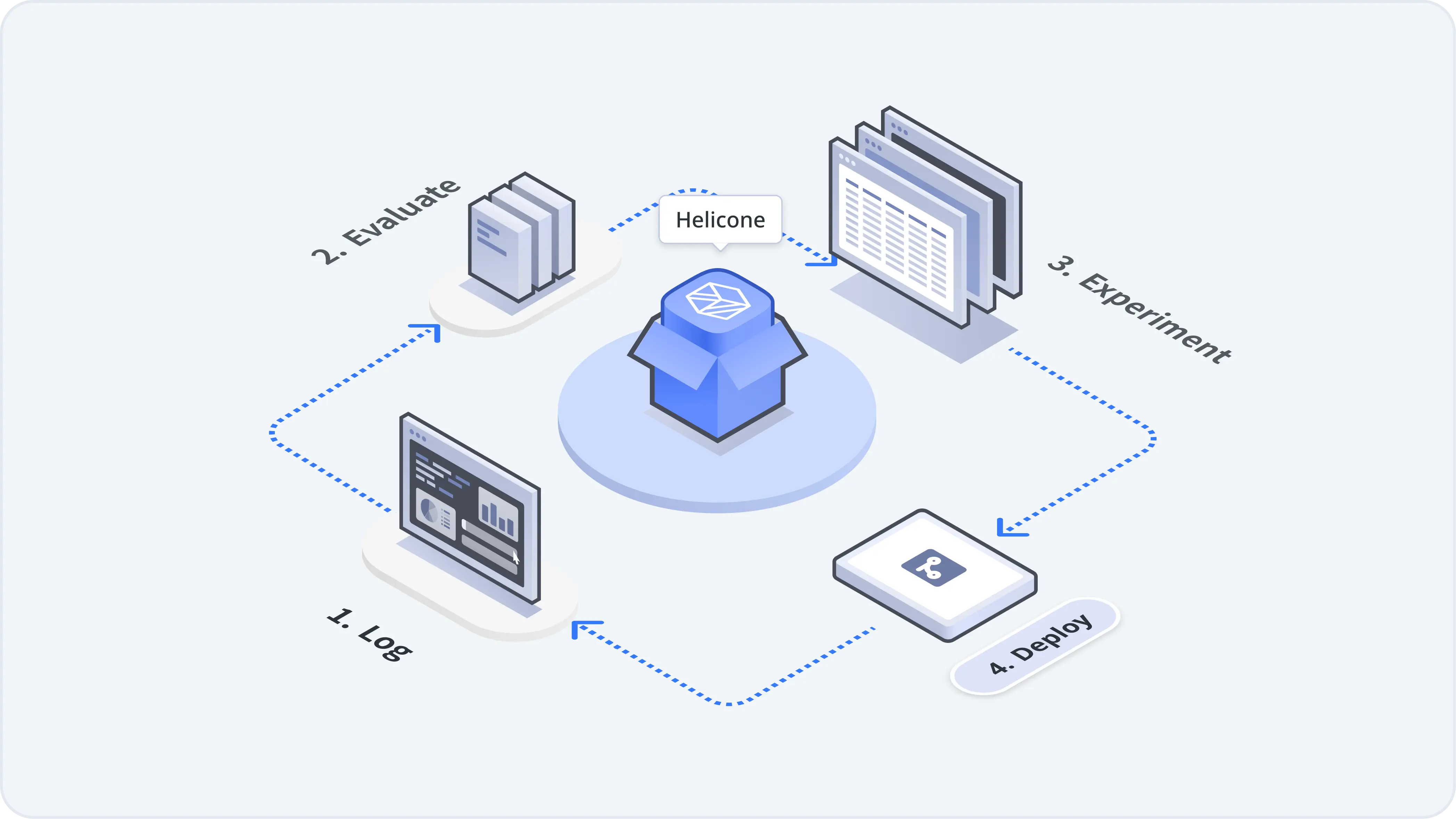 Steps to test your prompt: log > evaluate > experiment > deploy
Steps to test your prompt: log > evaluate > experiment > deploy
Preparation
Step 1: Log your LLM requests
Use an observability tool to log your LLM requests and track key metrics like usage, latency, cost, time-to-first-token (TTFT). These tools provide dashboards to help you monitor irregularity, such as:
- Rising error rates
- Sudden spikes in API costs.
- Declining user satisfaction scores.
This data helps you identify when it’s time to improve your prompt.
Testing Process
Step 2: Create prompt variations
Experiment with prompt versions using techniques like chain-of-thought reasoning and multi-shot prompting. Testing environments like Helicone makes it easier to track prompt versions, inputs, and outputs, while also providing rollback capabilities if changes lead to underperformance/regression.
💡 Pro Tip
You can create as many prompt variations as you need, where each tests one variable at a time (i.e. phrasing, model parameters) to isolate its impact.
Step 3: Use real data to generate outputs
Run your prompts on real-world datasets to ensure they can handle variability and edge cases. There are 2 options:
- Golden datasets with curated inputs with known expected outputs.
- Randomly sampled production data which is more representative of real-world scenarios (Here's why this approach is better).
Step 4: Compare outputs
Evaluate the performance of your prompts using the best methods that suits your goals and capacity, such as:
- Real user feedback for subjective insights.
- Human evaluators for nuanced assessments.
- LLM-as-a-judge for scalable and efficient comparisons.
Step 5: Push the best prompt to production
Once you've identified the best-performing prompt, deploy it to production. Remember to continue to monitor your application using observability tools to track metrics and identify opportunities for further refinement.
How to evaluate prompts before and after deployment
Evaluating prompts is about assessing how effectively your inputs—such as prompts and context—generate the desired outputs. Unlike generic model benchmarks, evaluations are tailored to your specific use case, providing targeted insights into performance.
Key evaluation methods
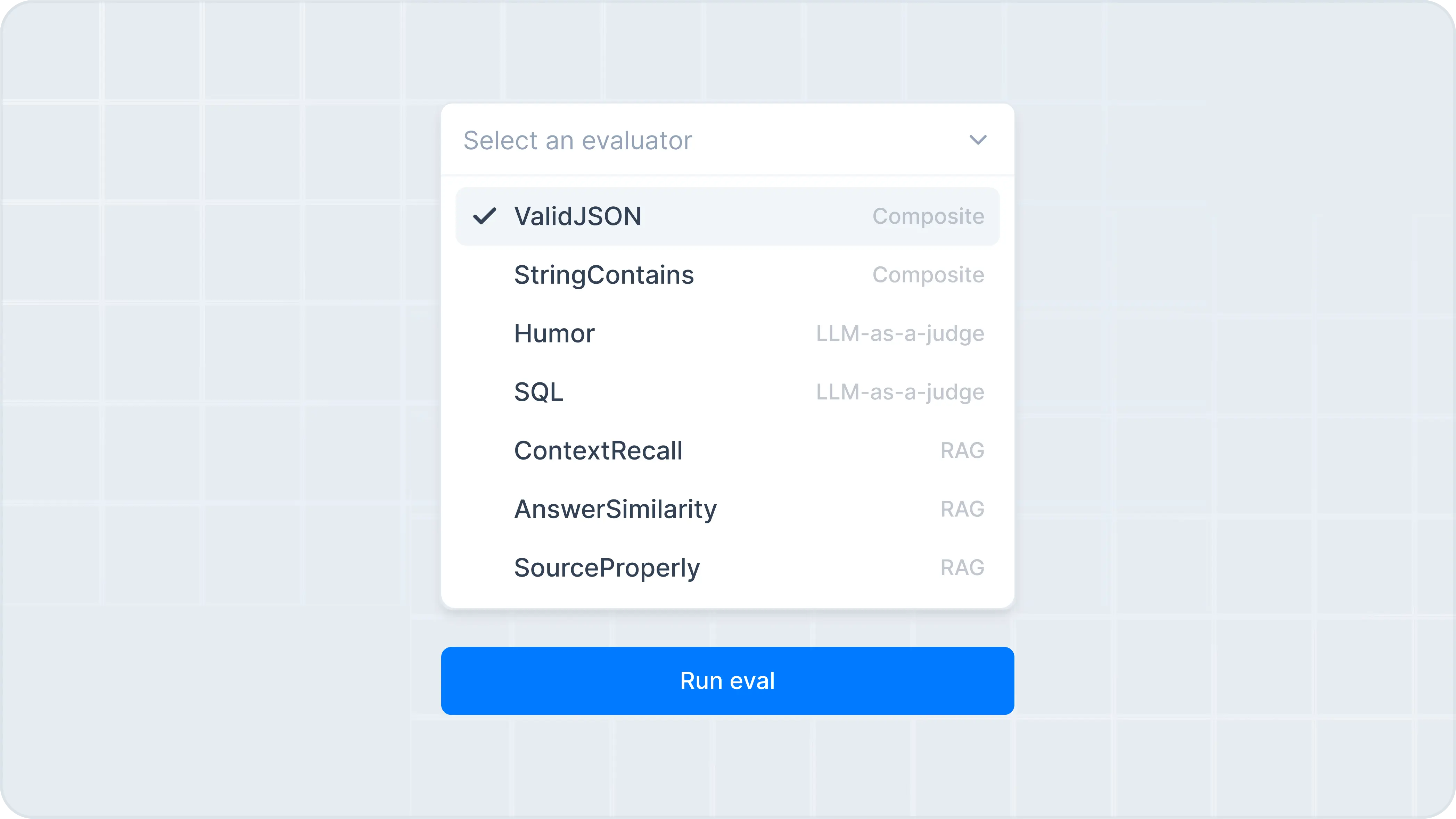
Add preset or custom evaluators to score your LLM outputs.
1. Real user feedback
Collect feedback directly from users to gauge how well your LLM performs in real-world scenarios. This can be done through feature implementation to solicit explicit feedback, such as thumbs up/down rating or scoring outputs, or by analyzing implicit user behaviors, like time spent engaging with responses or completion rates.
Bottom Line
Getting user feedback is very useful for understanding practical challenges, but it can be time-consuming and subjective. However, only when your users use your product over time, will you start receiving feedback to improve upon.
How can we evaluate prompts before deployment? Let’s look at some alternative evaluation methods.
2. Human evaluators
Use human reviewers to assess output quality based on specific criteria like relevance, tone, or correctness. This method usually begins with building a test dataset that human evaluators will compare the output against.
Based on the output, evaluators will score the response with yes/no, 0-10 (direct scoring) or is given a set of LLM responses where the evaluator will pick the better response (A/B testing or pairwise comparisons).
Bottom Line
Human evaluation is highly reliable for nuanced situations but is resource-intensive because the ground truth has to be constructed beforehand. It can also be subjective, leading to misinformation and much harder to scale.
3. LLM-as-a-judge
An alternative to human evaluation is using an LLM with an evaluation prompt to rate the generated outputs based on a criteria, especially for tasks like chatbot responses or complex text generation. This methods works well for both offline and online evaluations.
💡 What is online or offline evaluation?
Online evaluation uses live data and user interactions to capture real-world scenarios, while offline evaluation tests in controlled environments with past or synthetic data for safe, reproducible pre-deployment assessment.
Deterministic testing
LLM-as-a-judge is useful for scenarios where outputs are predictable and well-defined, such as:
- Classification tasks (e.g., sentiment analysis - positive or negative).
- Structured outputs (e.g., JSON validation).
- Constraint checks (e.g., ensuring no profanity or meet specific formatting rules).
Tips for success
- Test the evaluation prompt itself: make sure the prompt is clear and accurate.
- Use few-shot learning: Include good and bad examples to help guide the evaluation.
- Temperature setting: Set the evaluation LLM’s temperature to 0 to ensure consistent answers from LLMs.
Bottom Line
This approach can approximate human judgment while being more scalable and efficient. But keep in mind that LLM-assisted evaluations can inherit biases from training data, and may or may not outperform human evaluations. Creating an effective evaluation prompt is critical for this method to see reliable results.
Why evaluating prompts is important (and difficult)
To optimize your LLM application, you need a way to quantify its performance. Choosing the right evaluation method is just as important as the evaluation itself because different evaluators are better suited for certain use cases. For example:
An LLM chatbot designed for technical support will need metrics like:
- Whether the response directly addresses the specific issue raised by the customer.
- Whether the response avoids contradictory information or irrelevant "fluff."
- Whether the tone is appropriate (e.g., helpful and professional).
An LLM handles creative tasks (i.e. stories or marketing copy) will need metrics like:
- Whether the response is original, interesting and concise.
- Whether the response is aligned with brand guidelines or follow the desired tone.
- Whether the response adhere to structural requirements (e.g., word count, formatting).
Choosing the right metrics
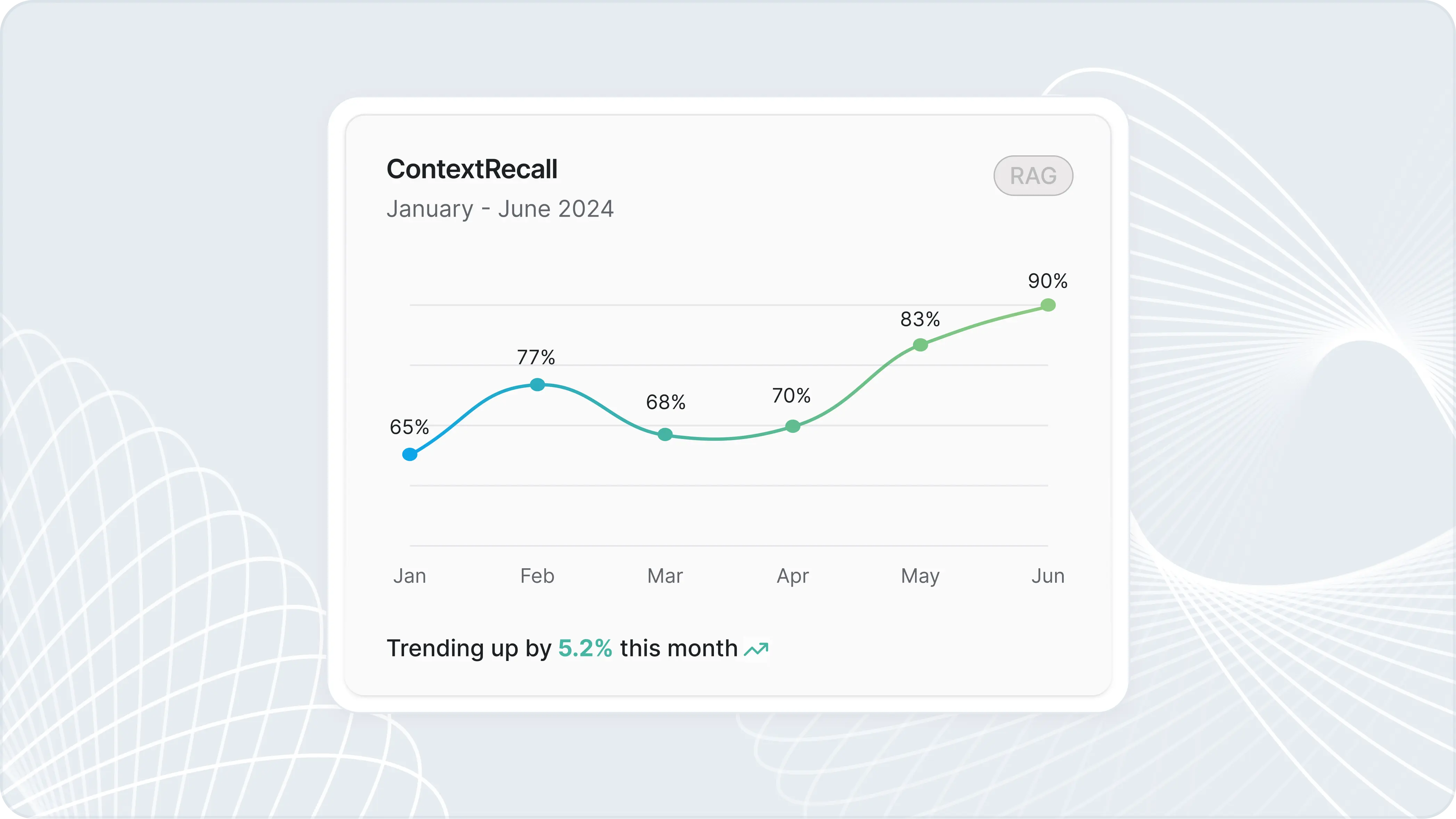
At the end of the day, the choice of evaluation metrics depends on your application’s goals. For example, faithfulness is ideal for Retrieval-Augmented Generation (RAG) applications to measure how well the AI response adheres to the provide context, while metrics like BLEU or ROUGE are better for translation-specific tasks and text-summarization tasks respectively.
Real-world examples
To evaluate LLM outputs effectively, start by identifying the specific aspect of the response you want to assess:
- Accuracy: Does the response answer the question or solve the task?
- Fluency: Is the response grammatically correct and natural-sounding?
- Relevance: Does the response stay on topic and meet the user's intent?
- Creativity: Is the response imaginative or engaging?
- Consistency: Does it match prior outputs or user inputs?
a) Measuring accuracy
Example:
A chatbot answering a factual query “What is the population of France?”
Recommendations:
- Reference scoring: Compare the output to a predefined ground truth for correctness.
- Human evaluation: Use for nuanced questions or when ground truth is unavailable.
- Word-level metrics (e.g., BLEU, ROUGE): Measure token overlap between generated and reference outputs for precise tasks.
b) Comparing two prompt versions
Example:
Testing whether an updated summarization prompt performs better than the previous version.
Recommendations:
- A/B testing: Put outputs side-by-side for human evaluators or users to pick the better one.
- LLM-as-a-judge: Automate A/B testing by using a carefully-designed evaluation prompt.
c) Evaluating edge cases or critical outputs
Example:
Assessing a medical assistant recommending treatment options.
Recommendations:
- Human evaluation: Involve domain experts to ensure safety, reliability, and compliance.
- Reference scoring: Use authoritative sources to build a dataset as benchmarks.
- A/B testing: Experiment with a modified prompt or tweak model parameters to improve accuracy.
d) Measuring usability
Example:
A virtual assistant handling user queries in a help desk scenario.
Recommendations:
- Real user feedback: Analyze explicit ratings (e.g., thumbs up/down) and implicit behaviors (e.g., engagement time or rejection rates).
- Human evaluation: Pre-deployment tests for adherence to tone, accuracy, and helpfulness.
e) Assessing creative outputs
Example:
Generating a poetry or brainstorming a story idea.
Recommendations:
- Scoring: Use human evaluators to rate outputs on creativity, coherence, and adherence to style guidelines.
- Human evaluation: Crucial for subjective tasks where creativity and engagement matter most.
- LLM-as-a-judge: Automate creative evaluations using fine-tuned models if cost or scalability is a concern.
Bottom Line
Ultimately, you want to make sure your LLM outputs align with user expectations and deliver an enjoyable experience. A tight feedback loop with your users is key.
There’s no hard limit on how many variations of a prompt you should test as prompt engineering is iterative. Whether you're just starting or optimizing at scale, keep iterating and experimenting.
Ship your AI app today ⚡️
Monitor, debug and improve your LLM application with Helicone.
Questions or feedback?
Are the information out of date? Please raise an issue and we’d love to hear your insights!